分布式id
随着系统越来越复杂,数据越来越多后,势必会引入分库分表。此时db本身的自增id将无法满足需求,这时将引入分布式id来满足需求。以下是几种生成分布式id的方案。
数据库自增id
思路
- 引入一个数据库(称呼为id数据库),创建一个id表
- 每次插入数据前,先来id数据库插入一条获取,获取一个自增id作为数据的id
优点
- 实现简单
缺点
- 不是高可用。一旦数据库挂掉,分布式id将无法使用
- 性能损耗大。
- 整个交互过程设计了网络开销
- 数据库硬盘IO开销
- 数据库并发数量上限将成为服务的插入数据的并发上限
数据库多主模式
在单个数据库基础上,为解决高可用问题,引入多个主数据库。
思路
- 各个数据库通过
新id = 不同的步长+原id的方式获取id(避免重复id) - 新增后台服务,通过负载均衡的方式从不同的数据库获取id
优点
- 高可用
- 相较单主数据库的模式大大缓解了并发的压力
缺点
- 步长和初始id值定下来后,数据库水平扩展比较困难
Redis INCR 命令
思路
- 需要获取id,则请求Redis执行 INCR 命令获取一个自增的id
优点
- 实现简单
- 并发性能高
缺点
- 不是高可用。由于Redis集群是异步复制的,所以为了避免重复id只能使用单机Redis
- 仍然存在不小的网络性能开销
UUID
优点
- 实现简单,各语言自身类库都存在相应方法
- 本地生成,没有IO开销
缺点
- 长度太长。MySQL官方建议主键越短越好,而UUID长度是36个字符长度,作为主键会很浪费空间资源
- 乱序。作为数据库主键容易引起裂页。
- 时钟回拨。可能导致重复id
雪花算法
Twitter推出的Snowflake 算法,用于分布式id生成。
思路
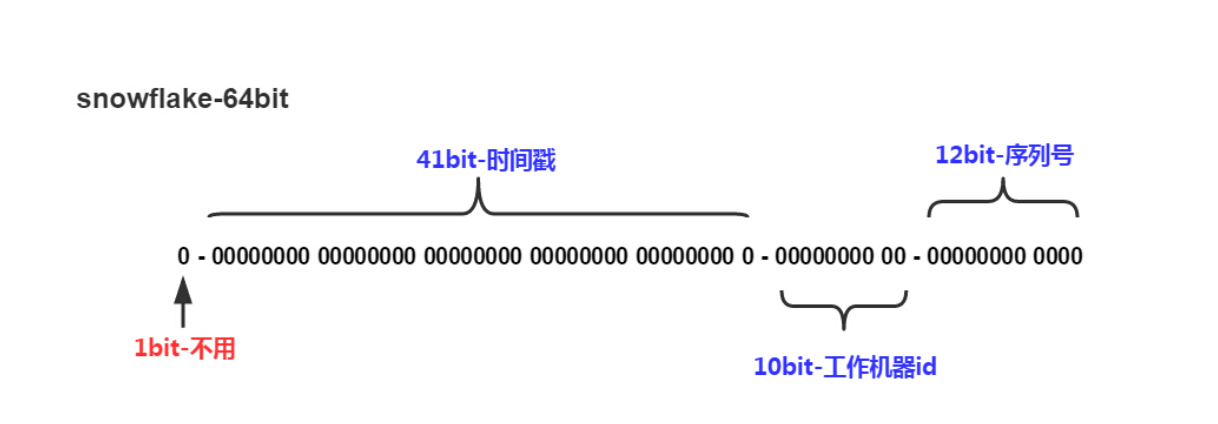
简单描述
- 最高位是符号位,始终为0,不可用。
- 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截) 后得到的值,这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序SnowFlake类的START_STMP属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
- 10位的机器标识,10位的长度最多支持部署1024个节点。
- 12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
加起来刚好64位,为一个Long型。这个算法很简洁,但依旧是一个很好的ID生成策略。其中,10位器标识符一般是5位IDC+5位machine编号,唯一确定一台机器。
优点
- 在单机上是单调递增的。在分布式系统里,如果没出现时钟回拨,则是趋势递增的。
缺点
- 长度太长。MySQL官方建议主键越短越好,而UUID长度是36个字符长度,作为主键会很浪费空间资源
- 时钟回拨。可能导致重复id
号段模式
每一次请求生成id都会获得一整个号段。
优势
- 保证了趋势递增
- 降低了生成分布式id服务的并发量
- 减少了生成分布式id服务的IO开销
Redis INCRBY 命令
INCRBY key increment
思路
- 需要获取id,则指定步长请求Redis执行 INCRBY 命令获取一个id
- (id-increment,id] 为获取的号段
优点
- 实现简单
- 并发性能高
缺点
- 不是高可用。由于Redis集群是异步复制的,所以为了避免重复id只能使用单机Redis
美团 Leaf
Leaf-segment
思路
- 建表
CREATE TABLE `tiny_id_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`biz_type` varchar(64) NOT NULL COMMENT '业务类型,不同的业务id隔离',
`max_id` int(11) NOT NULL COMMENT '当前最大可用id',
`step` int(11) NOT NULL COMMENT '号段的长度,也就是步长',
`version` int(11) NOT NULL COMMENT '乐观锁,每次更新都加上version,保证并发更新的准确性',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='db号段表';
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
- 提供一个分布式id服务按步长获取号段,用完再取
- 双buffer。当号段使用到一定数量时,多线程异步去数据库获取加载下一个号段
优点
- 方便线性扩展
- 容灾性高。服务内有号段缓存,即使DB宕机也能保证短时间内的正常服务
- 双buffer保证了不会因为没有号而导致的请求阻塞
缺点
- 不是高可用
- 单个数据库存在并发性能瓶颈
Leaf-snowflake
思路
在雪花算法的基础上,通过使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。避免当服务集群数量大时,手动设置workId的成本。
滴滴TinyId
基于 Leaf-segment。
特性
- 增加了多DB支持,保证了DB的高可用
- 增加了客户端SDK。由服务端生成号段,客户端根据号段生成id。降低了网络IO开销
- 客户端引入双号段缓存,避免了号段用完重新获取号段的等待时间。并且提高的容灾性